在當今數據驅動的時代,處理海量數據已成為企業的核心競爭力之一。Hadoop,作為大數據領域的基石,其重要性與日俱增。本文將從資深架構師的視角,為您系統性地剖析Hadoop的核心技術棧與服務生態,助您快速構建全局認知。
一、Hadoop的基石:核心組件深度解讀
Hadoop并非單一軟件,而是一個由多個關鍵組件構成的生態系統,其核心在于分布式存儲與分布式計算。
1. HDFS:數據的可靠倉庫
Hadoop分布式文件系統(HDFS)是整個體系的存儲基石。它采用主從架構:
- NameNode:作為“管理員”,負責管理文件系統的命名空間(如目錄樹、文件元數據)和客戶端對文件的訪問。它是集群的單一故障點,因此高可用方案至關重要。
- DataNode:作為“倉庫管理員”,負責存儲實際的數據塊,并定期向NameNode報告其存儲的塊列表。數據默認會冗余存儲三份,分布在不同機架上,確保了數據的可靠性與高可用。
2. MapReduce:經典的計算引擎
這是Hadoop最初的并行計算編程模型。其思想是“分而治之”:將一個大任務拆分為多個小任務(Map階段),在集群中并行處理,再將結果匯總(Reduce階段)。雖然如今更多被更高效的計算框架替代,但理解其“移動計算而非移動數據”的設計哲學,對掌握分布式計算精髓至關重要。
3. YARN:集群的資源管家
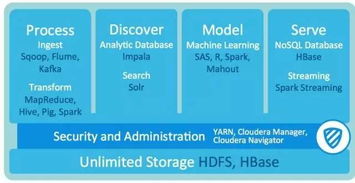
隨著生態發展,Hadoop 2.0引入了YARN(Yet Another Resource Negotiator),它將資源管理與作業調度/監控功能分離。YARN由一個ResourceManager和多個NodeManager組成,負責統一管理集群的計算資源(CPU、內存),并為上層應用(如MapReduce、Spark、Flink)提供資源調度服務。這使得Hadoop從一個單一的計算系統演變為一個多應用的數據操作系統。
二、Hadoop的利器:關鍵技術服務與生態
單純的核心組件不足以解決所有問題,圍繞其形成的豐富生態才是Hadoop強大的真正體現。
* 數據倉庫工具:Hive
對于熟悉SQL的分析師而言,直接編寫MapReduce程序門檻過高。Hive應運而生,它提供了類SQL的查詢語言(HQL),可將查詢自動轉換為MapReduce、Tez或Spark作業,極大地降低了大數據查詢的門檻,是構建企業數據倉庫(EDW)的常用選擇。
* NoSQL數據庫:HBase
當需要實時隨機讀寫海量數據時,HDFS的順序訪問模型不再適用。HBase是一個構建在HDFS之上的分布式、面向列的NoSQL數據庫。它能提供毫秒級的低延遲訪問,適用于實時查詢、增量數據更新等場景,是Hadoop生態中實現在線業務的關鍵。
- 數據采集與傳輸:Flume, Sqoop
- Flume:一個高可用的分布式海量日志采集、聚合和傳輸系統,擅長從各種數據源(如Web服務器日志)實時流入HDFS或Kafka。
- Sqoop:用于在Hadoop與結構化數據庫(如MySQL, Oracle)之間高效傳輸批量數據的工具,是傳統數據倉庫與大數據平臺之間的橋梁。
* 工作流調度:Oozie
在大數據平臺中,數據處理任務往往復雜且相互依賴。Oozie是一個工作流調度引擎,可以管理和協調多個Hadoop作業(如MapReduce, Hive, Pig, Sqoop)按照特定的時間或依賴關系有序執行,實現流程自動化。
三、架構師的實戰視角:技術選型與規劃建議
- 明確場景,選擇組件:
- 離線批處理與分析:首選 Hive + Spark(計算引擎)。Spark因其內存計算、DAG執行引擎,性能遠超MapReduce。
- 實時計算與流處理:考慮 Spark Streaming 或 Flink,它們可與HDFS、Kafka等無縫集成。
- 實時交互查詢:可選用 Impala 或 Presto,它們提供低延遲的SQL查詢能力。
- 海量數據隨機訪問:HBase 是不二之選。
- 集群規劃與高可用:
- 規模預估:根據數據量、計算復雜度、增長預期規劃節點數量(通常區分Master節點和Worker/Slave節點)。
- 高可用部署:務必為NameNode和ResourceManager部署HA方案,避免單點故障導致集群不可用。
- 資源隔離:利用YARN的隊列管理,為不同業務部門或任務類型劃分資源池,保證關鍵任務資源,提升集群整體利用率。
3. 未來趨勢與云原生:
傳統自建Hadoop集群運維復雜。當前趨勢是擁抱云原生和存算分離。例如,將數據存儲在 對象存儲(如AWS S3, 阿里云OSS) 上,計算集群按需彈性擴縮容,或者直接采用云廠商提供的 E-MapReduce 等托管服務,以降低運維成本,聚焦業務價值。
****
理解Hadoop,關鍵在于掌握其“分布式存儲”與“資源統一調度”兩大核心思想。整個生態系統都是圍繞如何更高效、更便捷地在這兩個基礎上存儲和處理數據而展開。作為架構師,不應局限于某一組件,而應通盤考慮業務需求、技術特性、團隊能力和運維成本,在Hadoop豐富的技術圖譜中選擇最合適的組合,構建穩定、高效、面向未來的大數據平臺。從HDFS/YARN的基石,到Hive/HBase等上層應用,再到云原生的演進,這條技術脈絡清晰可見,掌握它,您就握住了開啟大數據殿堂的鑰匙。